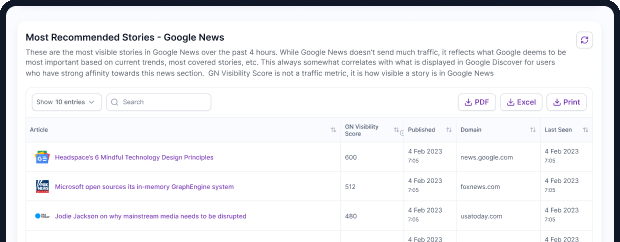
Semantic SEO for News Sites: Connecting News Related Entities based on Newsworthy Context






Article Written by Koray Tuğberk GÜBÜR
Semantic SEO is the connecting of sentences, topics, interests, concepts, and facts to create better context, and relevance. Semantic SEO is a universal SEO vertical for all of the verticals of the open web. Any kind of entity can be turned into a node within a knowledge graph to create a semantic and logical structure based on prominence hierarchy, or relevance hierarchy. Including News Industry, Semantic SEO strategies, and entity-oriented search understanding can help a source from the open web to have better rankings, and authority for its own niche.
For Semantic SEO to be used within the scope of News SEO, it is necessary to determine the prominence hierarchy between News Related Entities, to show the context strongly, and to show the relation types between the entities. Based on Historical Data, news published about the same entities in the past should be hosted in the same source and linked to each other with anchor texts using the correct annotations under the historical data and personalized content recommendation. As a semantic search engine, Google can more easily understand the semantic structured sites and will more easily match the related sites with different types of query templates.
In this article, Semantic SEO will be processed in the context of News SEO to help news sources to organize their websites to boost the contextual relevance of news articles for specific entities.
Table of Content
Before continuing further, let me introduce myself with a brief snippet:
Koray Tuğberk GÜBÜR is the owner and founder of Holistic SEO. I believe SEO is the intersection of coding and marketing along with a strong analytical thinking capacity.
What are News Related Entities?
News Related Entity is the entity that is the subject of the related news article. A news article can have multiple entities, and contexts. For this reason, Google, in its patents, calls the most prominent entity in an article "main entity". Main Entity is the main subject of the related news article, but the contextual domain may differ according to the relationships between the main entity and other related entities. For example, if you see the names of 5 Politicians, 3 Singers, and 4 F1 Drivers in a news article, they probably got together in the context of an event. However, when examining the "hyper structured data", the situation with Semantic Role Labeling may show that the main entity is the "event" itself.
To understand the main entity within a news article, and the contextual domain, search engines' perspective for named entities should be understood. In this context, the sections below will be processed in the light of Google Search Engine’s possible methodologies, and their terminologies to demonstrate the semantic nature of news SEO.
- Query Rewriting with Entity Detection
- Understanding Query Rewriting based on News Related Entities
- Interest-based Content Distribution for News Content for Named Entities
- Ranking the Interest-based News Articles for Named Entities
- Fresh Related Search Queries for News Related Entities
If you want to see the executable summary for the Semantic-News SEO, you can read the “Semantic News SEO Executable Summary” main subsection.
QUERY REWRITING WITH ENTITY DETECTION
Based on the entity within a query, or based on the entity within the document, the query of the user, and query of the document can be rewritten. Google has two different patent applications with the name of “Query Rewriting with Entity Detection”. When it comes to “query rewriting”, it is actually about “search intent understanding”, and “question generation” based on the selected dominant (main) search intent.
Query Rewriting can happen based on the query itself, and the latest trending searches along with the trends on the users’ behaviors. A search engine can choose different entities for query rewriting based on the context, or the prominent attributes of the specific entity can be used. Since, this patent has been filed in 2003, in the diagrams you can see the “Beta” addon for Google News. Also, Google was thinking of using the “Froogle” name for Google Shopping, and thus within the “product searches”, we have the “Froogle” logo. The main context here is that the search engine Google was thinking to use the entities, and the semantics for organizing the open web, including news for a long time. And, recognizing the entity, understanding the context, relating the other entities are the main keys here.
Below, you will see a query rewriting example from Google, for query rewriting. The query “harry potter store: amazon” is turned into the “Search Products for Harry Potter Amazon”.
Below, you will see a query-writing sample for financial news queries based on another entity.
“Mutual funds source: BusinessWeek” query is turned into the “search news for mutual funds business week”. The example above will be modified with a slight difference as below for query rewriting based on entities.
The query “mutual funds business week” query is turned into “Search news source business week for mutual funds”. This time, the “underlined section” within the rewritten query is more narrow because within the query, based on the entity, “degraded relevance ranking” has changed, and results include multiple sources at the same time.
UNDERSTANDING QUERY REWRITING BASED ON NEWS RELATED ENTITIES
Query Rewriting and News Related Entities are linked to each other as part of semantic SEO. If anchor texts, internal links, related entities in a news article are incomprehensible or missing, if the context cannot be selected, the related article will not be able to exceed the document relevance threshold in the query rewriting process.
When it comes to News SEO, since the news sources have a tremendous amount of content for even the last 2 days, query results, and click satisfaction become related to the “interests”, and “topicality”. Thus, query rewriting and “prediction of the search intent” based on the “degraded relevance ranking” are more important for News SEO. When it comes to news-related queries that are trending, they might be ambiguous due to the unclarity, and historical data. For instance, “the Biden explanation” query will change its “rewritten version” every day, because every day Biden (the 47th President of the United States) will make a new explanation, and the query rewriting process will follow it. Because of this “time”, and “data” deficiency situation, search engines will need to use the “interests”, “topics”, and “predictions”.
Search Engines have invented new methods to overcome the data vastness, time shortage, and high computation needs with “Predictive Information Retrieval” in the past. In other words, instead of checking all of the documents from the index for a search query, the search engine can predict the relevance to decrease the need for time, and resources to create a quality SERP.
[Demand-driven distribution of content]
Demand-driven distribution of content
Predictive Information Retrieval can be used to understand the duplicate documents based on simple repeated phrases across different documents from different sources, and it can be used to audit the query revision models. In this context, to decrease the document ranking, and re-ranking process, a search engine can try to find the set of initial necessities within a document and a news source. In the article “News Source Rank”, I have processed the importance of “breaking news score” by demonstrating the computational needs of search engines for news sources, predictive information retrieval can be processed within the search engine economy context the same way.
Search Engines can audit a news article whether it includes certain entities or not, whether the source has historical data for the same entity and topic with the past events. A search engine can check whether the news source satisfies certain criteria for interest and the audience with that specific interest. A search engine can predict the users’ future queries, and it can suggest different sources without query, based on the historical data for the satisfaction of the user from an interest.
Phrase-based detection of duplicate documents in an information retrieval system
In the context of query rewriting and news-related entities, if multiple documents have the same phrases within a sequence, the search engines can assume that these articles are duplicates of each other, and they should be clustered behind a representative version from an authoritative source.
Phrase-based detection of duplicate documents in an information retrieval system
A search engine can use the “Video on Demand” perspective for a news source, and if the news-related entities can be seen within the video of the news, or their voices can be recognized, it can have a better relevance, and query satisfaction possibility. Content format variation is a form of user interest in a topic. Users may prefer reading for certain topics while watching for other topics. Thus, covering both of the points of interest is better to improve the search intent coverage for the news source.
In the context of Semantic-News SEO, when a user searches for the “latest F1 crash from today”, the search engine will rewrite the query as “Watch 2021 Grand Prix X City Crash”, because most of the people will want to watch it. And, a semantic search engine can recognize the accent of the speaker, the voice of the person, the face of the named entities, logos, and temporal local actions. When it comes to entity-oriented search, it should be known that it is not only for textual data, also video content can be semantic too.
Besides the content format, predictive information retrieval, and query rewriting, the topicality, and interest of the user, and related interest areas should be understood for Semantic-News SEO.
INTEREST-BASED CONTENT DISTRIBUTION FOR NEWS CONTENT FOR NAMED ENTITIES
Interest-based content distribution for news content, and news audience is one of the most processed topics within the Google patents. Most news article re-ranking patents focus on two main things, these are source’s quality, and user’s interest. For semantic-news SEO, a news source should have the news-related entities together within the news article with the correct relation type between them by suggesting the historically important, and related other news content.
Below, from Google’s itself a possible search journey example will be demonstrated.
News topic interest-based recommendations
Like in the “Biden’s explanation” query example, a query can change its meaning during the Olympics, and even if a user is interested in sports, the Olympics, actually the user’s interest can be perceived differently. Thus, understanding the context of the news article, and the context of the user to match the search intent from the short timespan is important. Below, you will see the “News topic interest-based recommendations” the patent’s schema for the system. The point that I want you to pay attention to is the “CPU and Database” section. Because all of these algorithms increase the computation needs, the cost of quality query results shouldn’t be more than the cost of retrieving the document.
Below, you will see a design of content recommendation results from News.google.com based on the “News topic interest-based recommendations” patent.
For a user, a search engine can choose the related news articles based on “key sentences of the document”, and concepts, topics from these sentences for the user. It is closely related to the entities, and entity-oriented search. And, like in the “predictive information retrieval”, in this patent too, a search engine might not check the entire content to classify it, it can only check its description, introduction, or named entities within the core section based on topicality.
Below, you will see a news recommendation system sample from Google’s same patent for a news website. A search engine can evaluate a news source based on the quality of the news content recommendation system of the specific news source. If the news source suggests always the same articles for everyone without any kind of personalization, or contextualization, it might dilute the categorical quality of the article. Because, for news, the past news about the included named entities should be linked, and presented on the same web page based on the context.
RANKING THE INTEREST-BASED NEWS ARTICLES FOR NAMED ENTITIES
Choosing the related news articles for a user based on interest in the order to recommend, and ranking the same news sources for an area of interest are not the same things. The first task requires “creating community sections” based on IP Range, location, language, device, browser, gender, age, personality, and more. The second one is more generative, and representative. To rank a news article, a search engine can check the prominence of the news article based on a group of other related news articles. These related news articles are called “hub pages”, and in the hub pages, based on inter-connectivity, and comprehensiveness, clarity, a news article can be chosen as more prominent than others.
Identification and Rankings of News Stories based on Interest
To choose a news source, and news articles more prominent than others for interest, the search engine can check the related news articles ’ included entities, connected other news articles, anchor texts, linked news article’s headlines, and their past historical data for the specific interest area. Branded queries for a news source that includes a specific interest area can help a search engine to choose documents from the same source for the same interest area. For instance “Washington Post Finance News' query can help WP Finance-related news articles to be perceived more prominently. But, to accomplish these types of branded queries, the news source will need a semantically structured thematic news section. A search engine can use the website’s design, general navigation, or even the front-end HTML elements to give different news articles to different prominence measurements.
If a news source has multiple news for a specific entity, context, and topic, a search engine can check the “hub pages” to see which news is more prominent to be chosen as representative. The same methodology can be used across different news sources. Below, you will see a section from the “Identification and Rankings of News Stories based on Interest” patent.
Identification and Rankings of News Stories based on Interest
From social media shares, comments, branded query terms, click data, user selection over SERP, hyperlinks, to the entities, semantic closeness, source’s relevance to the topic, and related news articles’ internally and externally referencing methods can affect the prominence measure of the news article.
In this context, you will see that search engines design a model that can give different weights to the different references and hyperlinks for the news articles. The hierarchy on the web page and text distinctiveness affect the prominence measure.
Below, you will see that search engines can use the HTML Structure to assign different types of contexts, and relevance, or prominence to the news references.
Ranking the Interest-based News is important for Semantic-News SEO because it determines a news article’s prominence to be ranked via a group of hub pages, and the reference methodology. Also, based on the reference, and the hub pages, the targeted news article’s relevance level for an interest changes, and having the semantically structured contextual links, prepositions, facts, and news-related textual data is supporting the possible decisions of the search engine ranking algorithms.
FRESH RELATED SEARCH QUERIES FOR NEWS RELATED ENTITIES
A search engine can recognize the new and unique queries, also the query search-demand increases and decreases. Based on the sudden search-demand changes, a search engine can trigger the news exploration, processing, and ranking algorithms to satisfy the user’s “interest” for a certain topic. The “fresh related search queries” is a patent from the Google search engine to recognize the newly discovered, or fresh search queries to generate more “related queries”.
The important thing about the “fresh related” queries is that every newsworthy query includes a named entity, or an unnamed topic as a phrase, and a specific attribute for it. Thus, understanding and parsing the fresh related queries to improve the relevance and confidence is related to the Semantic-News SEO. Including the fresh query’s entity within the news article as the main entity is critical to use the Neural Matching systems of the search engine.
Below, you will see related fresh queries for a named entity.
Even if the web search results show the evergreen web pages with informative nature, you can realize that the fresh related queries include different types of attributes that have the “news” value such as “earthquake”, and “ city name'' with more specificity for the same attribute. Attributes within the queries for named entities can signal the context, and the newsworthiness of the demanded content, because while “earthquake” has a news value, the “North Korea flora” doesn’t have the same level of newsworthiness. Thus, even if the main entity within the news article matches the named entity within the query, the attributes might not be matched. If the newsworthy attribute of the named entity, and the attribute from the query are “related to each other”, probably Google will show a news carousel, or even maybe a top stories instance within the SERP.
Again, computation needs can be seen, and also “tracking component”, and “fresh query component” are more unique to this design.
Some of the Google Patents and “possible perspectives” above will be processed in further articles, but in the context of Semantic SEO and News SEO intersection, to create actionable insights, only the relevant parts will be processed.
SUMMARY OF NEWS RELATED ENTITIES
Below, you will find the things that are mentioned and told until now in the context of Semantic News SEO.
An entity can be newsworthy for a search engine.
An entity’s attribute might not be newsworthy for a search engine.
Search engines can have a tracking component to see sudden search demand changes for different queries.
Search engines can use phrase-based indexing to detect the duplicate and invaluable news articles.
Search engines can recognize hub-pages to measure the prominence score of the news article.
A search engine can detect entities within the news article to assign a context, or relation type between these entities.
A query can be rewritten by the search engine based on the entity within the query.
If the entity within the query has news value, the search engine can choose the news sources before the informative or commercial sources.
A search engine can suggest fresh trending queries to the user because of the ambiguity of the content.
A search engine can check the HTML Structure of a news source to understand the relevance of links within the website.
A search engine can check the visual closeness, and distinctiveness of the news headlines to assign them a prominence measurement.
A search engine can understand the interest of the user, and suggest new content based on the interest of the user.
A search engine can score the content recommendation system of the news sources.
If a news source doesn’t suggest the relevant documents based on the daily context, and the user context, a search engine can decrease the prominence of the news article for the specific news-related entity.
A search engine doesn't have to check every detail on a news article, it can use predictive information retrieval to decrease the computational needs.
A search engine can use predictive information retrieval to understand the main entity of the news article.
A search engine can rewrite a query differently, based on the time of the year, or weather of the day.
A search engine can rewrite a query based on the content format, such as “watch”, “listen”, or “read”.
Content format variations can support the confidence score of the relevance of the document with semantically structured information signals, such as names, places, voice detection, face detection, and context creation between detected objects.
A news search engine can determine the related newsworthy related phrases to calculate an information gain score for the different news articles.
A search engine can detect possible and potential newsworthy attributes for non-news related entities to generate possible news related queries.
A search engine can detect different possible newsworthy situations for a specific entity based on its type, such as “death”, “war”, or “crisis”. In this context, a search engine can detect the topic, and the main entity to gather the information from the news sources which have extensive amounts of authority, and historical data for the specific topic.
A search engine can divide a community based on IP ranges, geography, demography, language, device, browser, interest areas and more to understand which news sources are more authoritative for which news related topics.
A search engine can use the click data, selection rate, or read time, and uniqueness of the news source to evaluate the news article’s relevance, and news source’s success for a specific topic.
In the next section, newsworthy context, and its definition will be processed based on the Google search engine’s documents, patents, and guidelines.
What is Newsworthy Context?
Newsworthy context is the situation, angle, and perspective that has a news and interest value from the viewpoint of the audience. A context can have a news value based on its uniqueness, effectiveness, results, or historical value. A context can have more newsworthiness based on the news related entity. For instance, the death situation is newsworthy context, but the death of an ordinary citizen doesn’t have a newsworthy context while the death of a diplomat has more newsworthy context.
In this context, recognizing the main entity within the news article can be more useful for the search engine, if the context of the article can be understood. A main entity can have multiple types of news within a day, a person can marry one day, and at the same time they can have a scandal in their business life. In this context, we actually have two different newsworthy contexts for the specific main entity. All the related entities, and relation types, newsworthy attributes will change based on the context, and to match the different news related queries to the different newsworthy contexts, search engines will need to recognize the main angle of the content.
For instance, the president of a country can have 45+ news in one day within different contexts. He/she can be a main entity for a variety of different contexts from economy to sociology. And, every time, the related entities, entity types, and related phrases will change.
HOW CAN A SEARCH ENGINE UNDERSTAND THE NEWSWORTHY CONTEXT?
Based on this, a newsworthy context for a main entity can be collected with the variety of signals. A search engine can try to use the methods below to understand the context of the news article for a main entity.
Checking the URL Pattern, and thematic words, past articles from the same URL pattern
Checking all of the named entities within the article to find a mutual attribute between these named entities.
Checking the news headline for any kind of power word, predicate, situation related words.
Checking all of the anchor texts, linked articles, headlines and n-grams of the linked articles.
Checking query demand changes for the specific entity.
Checking the titles of the news articles for the specific entity for the last 48 hours.
Checking the news tags, images, videos, and places, faces, logos within the visual and textual theme signals.
Checking the adjectives, prepositions, nouns, compound words to understand the relation types.
Checking the introductory section to understand the main context.
AN EXAMPLE OF CONTEXT RESOLUTION FOR A NEWS RELATED ENTITY AND NEWSWORTHY CONTEXT
While I am writing this article, there was a big hype in the search demands based on Afghanistan. Since then, the Taliban has started to regain the territories in Afghanistan, Google changed the related SERP instances, and categorized all of the sources, news articles, and news related phrases.
Below, you will see an example of Google Trend Search suggestion for “Breaking News” when I started to type “Afg”.
Below, you will see the search suggestions for the specific entity.
“Kabul, Afghanistan”, and “Afghanistan news”, “Afghanistan army-military” are the fresh related search suggestions. Actually, “Afghanistan map” is also a fresh related search suggestion because it is to see the latest military situation within the war zone. Let’s check the web search section.
Naturally, we have a “Top Stories” carousel, and the “news” vertical is at the second order. All of the news have the “military theme” with the related phrases such as “troops”, “allies”, “fronts”, “evacuation”, and the Taliban’s itself already has a military theme too.
Below , you will see the web search results for the related blue links. We have the “City” names, “military words”, and news articles for only “war context”.
We also see that the “People Also Ask” questions section is not related to the news theme, or newsworthy contexts, it focuses on general facts over time. Below, you will see the auto-suggestions for the same main entity.
Again, all of them are war related. In this context, let’s choose the main entity, and its main context, along with the related entities and related sub-contexts.
Main entity for this news is “Afghanistan”, and the main context is “war and military conflict”.
The newsworthy attributes of the main entity are “military last situation”, “security”, “government”.
The related named entities are “United States, Taliban, NATO, Biden, Kabul”.
The predicates are “Withdraw, Conquer, Fight”.
The nouns and unnamed entities are “news, map, capital, today, war, reasons, troops”.
The sub-contexts are “evacuation of US Troops”, “reformation of Afghanistan”, “danger of Taliban”.
Based on this information, a news source should include the main and related entities within the beginning section of the article with clear connections. And, the main context should stay on the “military conflict”, the sub-contexts should be linked from the main news article.
Let’s check the sub-contexts and related entities that we actually explored with our manual observation with SEO mindset.
Search Engine actually created new entities already based on the latest events, such as “Diplomatic Mission”, or “Withdrawal of United States troops from Afghanistan”. The second one is an entity with history, so if your source has long historical data for the specific context and the entity, it will be chosen over the other sources.
And , as you can see the same topic connects with other related entities based on the same context. Such as “Joe Biden”, “Military”, “Withdrawal of U.S troops from Iraq”, and the country “Iraq” itself.
In the context of Semantic SEO, what kind of content can be created for these newsworthy entities and contexts? To clarify the answer of this question, we can check the other related entities and contexts.
When we check Joe Biden’s news carousels, we see that there are different types of contexts, and other related entities. Such as “Schools and Masks for Covid-19”, “Biden and his habits in White House”, “Biden and his supporters in Congress”, “Biden and Afghanistan”.
Let’s check other related entities together.
When we search for the “Taliban”, we see that there are some “sub-sections” within the news boxes, and their names are “For Context”. Every “for Context” section includes related news from the past from the same news source.
Below you will see these two “For Context” news section’s targeted news article’s headlines and their dates.
We have all of the related entities, related contexts, and relation types between these entities. The other important part is that both of these news articles are updated regularly, and this is clearly stated within the news article’s beginning section with the mark “Live” and “Updated X minutes ago” addons.
And, let’s change our focus a little bit. Afghanistan is an entity with the type of a country, it also has neighbor states such as Pakistan. Let’s check a closely related other entity that is not seen within our “context resolution analysis” for news-semantic SEO.
When we search for Pakistan, at the beginning, it seems like it is normal. But, let’s look a little bit below. You will see that all of Pakistan, and the new “trending search demand for Afghanistan” generated a new related context.
We have three different contexts with the main entity Pakistan. One of them is about a last night attack on civilians, the other one is about “Pakistan and Afghanistan'', and there are multiple sub-contexts there too.
The last section includes general news, and as you can see we have mutual news here. Some of the news that appears in Afghanistan main entity search, also appears in the Pakistan main entity search instance. In other words, these two entities are semantically connected to each other based on different contexts. Let’s resolve these newsworthy contexts.
First, together, we can try to think like a search engine. We have two entities, Afghanistan, and Pakistan, with the same entity type which is country. They both have a border as an attribute. And, these two main entities share the same border. A search engine knows that whenever a war related search query demand increase happens, also “border” related news, and queries will arise too. And, diplomats will make similar explanations, or declarations. So, the contexts can be found below based on this “pre-determined entity attributes, and connections”.
Afghanistan and Pakistan Border Conflict
Afghan refugees and Pakistan response
Pakistan President and Ministries explanations for Taliban and Afghanistan
Pakistan and Taliban relationship
Pakistan and its military power
Pakistan and its stance against Taliban
Let’s check the news headlines together.
These two are about Afghanistan and Pakistan relation, border and Taliban’s effect on it. Also, when it comes to Pakistan, we will need to include “China” for the context. Based on this, you will see some other news below.
There was a “suicide attack” on Chinese workers in Pakistan, and the blamed side was the Afghanistan. In other words, we have Pakistan, Chinese, and Afghanistan as the related entities and the attributes of “workers”, “foreign minister”, and the predicate of the “blaming”, and the noun-unnamed entity of “suicided attack”. We also have Huawei news, because it is a “Chinese company”, and it is blamed for spying in Pakistan. Below, you will see other related news within the Afghanistan and Pakistan context.
We have the entities of “Afghan diaspora”, “US” and “Pakistan Embassy”, along with “Taliban”, and the unnamed entities are “proxy war” along with the predicates of “protest”, and “being under pressure”.
Here, Foreign Affairs news article from 3 weeks ago ranks both Afghanistan and Pakistan main entities’ search instances. And, “women in Pakistan”, and “women in Afghanistan” are the same level of prominent attributes for the newsworthy context. Thus, based on another newsworthy event, we have “women rights” related news here. Below, we have a TRT World News for Pakistan and Afghanistan contextual domain.
Maybe, to the possible newsworthy context list, we can also add the “possible responsibilities” section too. Based on this context, a News SEO should think semantic SEO with the related terms, concepts, and the possible search engine methodologies to organize the information.
Based on the attributes of the main entity, and the possible questions that can be generated from these attributes, the newsworthy context can change. The main entity can have multiple newsworthy contexts, and a news source should process all of these related main entities based on possible newsworthy contexts by connecting all of these entities, contexts and situations to each other with the proper internal links, and semantic annotations.
For instance, to demonstrate the context from beginning, so that the “predictive information retrieval” and the “phrase-based indexing” for possible related co-occurrence analysis to determine the contextual domain can be done faster, and more efficiently.
Try to use annotation text if you want to use a “generic term” within the anchor text. Since, “U.S Intelligence” is another entity, and also has many potential newsworthy contexts, connecting this anchor text to the U.S Intelligence News Category would be better, but if you want to use a “predicate” with it, include the “Kabul” or other types of related entities within the same sentence, so that search engine can relate the two different pages better based on semantic closeness.
Above, there is another example for the NY Times. The related entities such as “Afghan government”, “Taliban”, “U.N” and related attributes such as “strategy”, “districts”, “border”, and predicates such as “crossing”, “abandoning” can signal the relevance of the anchor text to the targeted news article better. If you remember the “prominence measurement” and the “hub-pages” examples from the previous sections, you will be able to see the efficiency relation of these practices to the semantic-news SEO.
Below, you will see a news recommendation sample from New York Times, for the same topic.
And, as you can see the dates, the headlines, and the “group of articles’” name are clear. “The fall of Afghan Cities”, which resonates with the fresh related search queries such as “Afghan City”, or “Kabul, Afghanistan”. All of the related articles are linking to each other based on the same context, main entity by including all of the related entities and attributes.
And, as in the Reuters sample, having a subtitle, video content, and visually descriptive sequential images with caption texts will also help to improve the search intent coverage based on the query-writing for the main entities in terms of newsworthiness and their contexts.
Since the article has many theoretical sides for the Semantic-News SEO, I wanted to cover a section with practical analysis, in the future sections we will examine context related Google Search Engine patents for news content distribution, and recommendation.
CONTENT RECOMMENDATION BASED ON CONTEXT FOR NEWS SEO
Based on the context, a search engine can recognize a topic, and classify the same news articles from the same context. It can differentiate the main context from the sub-contexts, along with the entities, and entity relations within the news article. If someone reads for US Troops Withdrawal from Afghanistan, they can also read the “Withdrawal of other countries from other countries”, or the “sending troops to a country by another country”.
A section from Content Recommendation based on Context
They can wonder the reasons, causes, similar events from the past, and responsible ones of the situation. Thus, for a search engine, satisfying the possible interests, and potential search activities of the user is important. In the past, based on semantic search engine features, they have announced a couple of updates such as “sub-tropical update”, or “passage ranking”, and “conversational search”, or “MuM”. All of these announcements touch two specific terms for semantic SEO.
Degraded Relevance Ranking
Possible Search Activity
With uncertainty, a search engine can predict a user’s possible search activity based on an interest, and it can suggest the user a document, a query, or even a product, and movie directly. Thus, the search engine optimization with semantic principles in terms of News Industry should be taken into consideration with these possible “search activities” and “degraded relevance ranking”.
A news article can be more relevant to Afghanistan’s economy for the next 25 years after the Taliban invasion/conquest than Afghanistan’s sociological changes.
I have written the query with a typo on purpose.
And, if you check auto suggestions of Google for the specific entity, you will realize many different contexts, and interests. Some of these autosuggestions are related to sociology, and more relevant to the future such as “Can afghanistan speak Hindi”, and the rest is about a possible outcome of a war, like defending, dividing, conquering, surviving, beating, and more.
Thus, if someone reads one of the topics above, search engines will see other ones as relevant for the possible search activities. In this context, semantic news SEO is also about topical authority. Covering a semantically connected entity network with different attributes for fresh content needs, by connecting all the news to each other.
Half of a diagram from Content Recommendation based on Context
As a last addon for the “content recommendation based on context”, a search engine can track the engagement of the possible connections of the entities from a knowledge graph. A sample from Google's own patents below.
If Afghanistan and Taliban main entities with the context of war take too much attention with high search demand increase suddenly, search engines can improve the rankings of other related news articles, and articles with similar contexts, or main entities. Having trending, or trend-related entities, phrases and themes within a source is an advantage to improve the prominence of the source to a topic.
Note: Whenever I see the name of Krishna Bharat within a Google Patent, I definitely read and take it into account for SEO.
If you want to learn more about context and search intersection, you can read the article that I have prepared before.
NEWS ARTICLE GROUPING BASED ON FRESHNESS AND TOPIC
Not just for a topic, but also for freshness, a search engine can group different news sources, or news articles. If a news source has more fresher content for a topic, for the latest trend, it can be prioritized on the SERP. But, also grouping based on freshness and topicality can have its own tricks.
A search engine can check the social media networks to see highly engaging content. To group them a search engine can group the social media users before grouping the news sources, or the news entities.
After identification of a topic, a search engine can give a category to a news source, and also a categorical quality score.
Search engines’ main purpose is to group the documents based on time, and the topic is decreasing the overwhelming content amount for the news readers. By filtering the news sources based on topic, and by filtering the news articles from these news sources for specific news topics based on time, only a small number of high quality, and reliable news articles will be presented to the users.
During this filtering process, a search engine can understand the engagement rate, and possible new news, or news related fresh queries, attributes, and contexts. Purpose of grouping is not understanding the news article, but improving the overall quality of the filtered news sources.
A search engine can define an event based on the different entities. If the event is “withdrawal of US troops”, or “Fall of Kabul to Afghanistan”, a search engine check the article’s date, the first related query’s date from the query logs, and the differences between the firstly published and later published articles to see whether a new news article should be ranked higher than the first discovered news articles.
To group the news articles, a search engine can only check their titles. Thus, like in the example section, the entities, attributes, and the predicates, or the power words within the title are important. An article can be filtered differently based on the entity within the title.
A search engine can cluster the words, n-grams, bigrams, or the 55trigrams, entities, attributes, and semantically parse close words from news articles. If the news article’s headline includes a centroid word for a cluster, or if the title has a representative, and generative thematic word, it can have a heavier weight to relate the news article for a specific topically clustered news article.
You should remember the query-writing based on the content format, in this section.
Based on the defining words within the news title, a news article can be perceived differently, such as as a video news, news brief, letter to the editor, or opinion, critics, investigation and more. Beyond the news title, same news article qualifiers can be taken from the news article’s itself, or its tags, introductory section, or the named author’s itself.
Not entirely related to the Semantic-news SEO, but it isi important to understand the “Recency Score” for a news source. A source can be more related to a topic, and thus, a news source can publish an article late, but still it can be perceived as fresh due to the extensive amount of historical data. I am sure that as a News SEO you have used a simple complaint sentence such as “They published it later than us, and they have taken the rankings”. It happens because of the Recency Score, and the News Source Rank relation.
BROWSING THE HISTORICAL CONTENT
Historical content, or historically important content, and information is important for search engines to see the permanency of the related news source for a topic. Browsing historical content based on a news source, an entity, and a topic, or context is important to give a news story’s behind, or the background. Thus, besides grouping the fresh news content, also keeping the old news content as grouped and browsable, or relatable to the latest events is important. To help a search engine to relate the old content to the new ones, based on context, or an entity, a news source can use semantic-news SEO methodologies via entity oriented search.
Above, you see a news historical graph within a time window for specific contexts, or knowledge domains.
Based on the time window, and the search qualifiers, different types of news articles can be grouped together. Since, the related patent is from the early days of news.google.com, it still has the “Beta” addon within the Google News Logo.
Again, for Afghanistan, we can see the related news sources, and topics along with irrelevant entities for the latest main newsworthy context such as Afghan Hound. Based on this, a search engine can show the news from the last month, and also it can collect feedback from the users whether it is intentional feedback or not.
Below, you will see a similar design from the patent from 18 years ago.
A news sample with a “date” within it can be seen below.
In a similar way, when you determine a date within the search bar, you get news that is closer to that specific timeline whether it is year, or the month.
In the context of Semantic SEO, having timely close and related news together within a web page, or a news source, might improve the browsability of the specific news source in the eyes of search engines.
In the context of topicality, interest, freshness, and document filtering based on quality for News SEO, you can check the Google Patents below.
Phrase-based detection of duplicate documents in an information retrieval system
Demand-driven distribution of content
News topic interest-based recommendations
Identification and Rankings of News Stories based on Interest
Fresh Related Search Suggestions
Content Recommendation based on Context
Clustering news online content based on content freshness
Browsing Historical Content
Next sections will include executive summary for Semantic News SEO.
Semantic News SEO Executable Summary
Semantic News SEO is the SEO effort that adopts semantic SEO principles for news organizations, and news related queries. To be successful in the News SEO, a person might need years of experience. To improve the News SEO project’s success, semantically connected topics, interests, entities and their attributes should be analyzed, and with the news headlines, news introductory sections, news article links, URL patterns and more
To learn the semantic SEO principles and strategies for News SEO, you can check the brief supporting sections below.
HOW TO CONNECT ENTITIES TO EACH OTHER IN A NEWSWORTHY CONTEXT?
A main entity’s newsworthy context can be taken by checking its type, attributes, queries for it or parsing the news titles. For a person with this type of politician, the newsworthy context can be a simple trip, or explanation, declaration, interview, or a meeting. For a person with this type of footballer, it can be marriage, transfer, latest performance for the football matches, and more.
If you want to focus on an entity, you should take all of the possible attributes for it. For instance, below the main and most important attribute for Cristiano Ronaldo (soccer player) is football.
Same entity can also have “marriage” and “spouse” attributes, and related news.
If search engine doesn’t have enough news for the specific entity and newsworthy context, it can choose another entity from the same entity type such as “Pele”, and it can focus on the children of the same entity, or “Supermodels” since the Christiano Ronaldo’s wife Georgina Rodqiguez is a supermodel. In this example, a News SEO Project can use different contexts by connecting the different news related entities.
Open a biography page and news categorization, aggregation page for Cristiano Ronaldo
Include all of the historically prominent news content for the specific entity.
Categorize all of the specific news for the entity by different contexts.
Unite all of the other related entities from the same type with the same contexts.
These contexts can be “football players from 21th century”, “football players from X club”, “spouses”, “children”.
From every news article, the related entities should be linked by specifying the context.
For instance, from Cristiano Ronaldo, his spouse Georgina Rodriguez can be linked with the correct relation type. From the news of the Georgina Rodriguez, the supermodel news, or footballer spouses can be linked too.
Every contextually relevant link will help a search engine to group, filter, understand and relate different news articles to each other for different types of trends, and queries.
WHAT IS SEMANTICALLY CORRECT STRUCTURE FOR A NEWS SOURCE?
For every news content, and main entity, newsworthy context, a news article can have a different semantic structure. A news article for football, and a news article for war can’t be written in the same way. A news article for critics, and a news article for entertainment, again, can’t be written the same way.
For a war related news article:
For a news article about war, the article can have the entities with the type country, politicians, sociological unnamed entities such as immigration, or border crossing.
For a news article about war, the news article can have a summary at the beginning.
The result, and the latest updates can be told after the summary.
The past related declarations, news, and other updates can be detailed, and linked for related contexts from the main content.
At the end of the content, the other past related news articles can be linked.
This is a semantic news article structure example from Axios. Definition of news, importance of news, and “hub-type” section with different prominent resources are presented within an order.
For a sports match related news article:
For a news article about a sports match, the article can include the team names, director names, stadium name, result scores, important minutes from the match, and attacks, defenses, most successful players names, goal-score uniqueness and more.
All of this information can be presented within an HTML table in a structured way.
All the team names can be linked to the specific entity page.
All the team articles can be linked to the “National X League” section.
All the National X League sections can be linked to the Global X Games.
All the Global X Games can be linked to the X News’ itself.
A section from the book “Writing for News Media” from Ian Pickering. Creating a semantic structure for a news article shouldn’t mean repeating the competitors, or repeating the same structure for every specific entity, and its possible situation.
For an economy related news article:
Stock prices can go down, in this context, all of the company sections can be linked.
All of the CEOs, and managers can be linked.
The economy minister’s explanation can be linked.
The exceptions for the stock prices crisis can be mentioned within a separate article.
The reasons can be written by linking the related articles.
The other valuable and tradable sections, and entities can be linked with the same way.
Within the article, the date, the percentage, the stock names can be given within a graph, and with the latest explanations, and comments.
From an economic observation web page, the related critics, and other news articles can be linked.
The general economy of the country, and the global economy also can be linked.
To connect all of the related entities, and contexts to each other, the named entities, their attributes and their prominence for the specific news article should be followed. If the prominence hierarchy can’t be created in a correct way, the semantic structure might not improve the search intent coverage.
WHAT IS THE MAIN CONTEXT FOR A NEWS ARTICLE?
Every news article has a context. A context can be economy, or economic growth, or slowing down economic growth, or reasons of slowing down economic growth, or explanation about the reasons for slowing down economic growth. When a main entity within the trends, a news source should list all of the possible newsworthy contexts, and it should cover all of them by connecting them to each other.
In this context, for Afghanistan news, the contexts can be as below.
Can Taliban attack Iran, Pakistan, China, Russia, Tajikistan, Uzbekistan, Kırghizstan?
Can Afghanistan defend itself?
Will the US intervene in the situation?
What are the NATO explanations?
How many refugees will immigrate to other countries?
Who is responsible for this outcome?
Why has the Afghanistan Army failed?
How many billions of dollars are spent for the Afghanistan Army?
What is the demography and sociology point of view for this outcome?
Evacuation of the NATO forces
Taliban’s Political Stance
World Opium Trade
Joe Biden’s explanations
Critics for Joe Biden
Explanations of neighbor countries
All of these contexts, and all of the other related main entities such as countries, politicians, institutions should be processed and grouped, by interlinking each other with the correct semantic structure.
HOW CAN A SEARCH ENGINE PERCEIVE A NEWS ARTICLES’ UNIQUE VALUE?
To understand the unique value of a news article for a context, and a main entity, search engines can check the facts, prepositions, related entities that are included, and the unique sentence count within the news article. News source and the time of the news article publication also can affect its unique value. Because, when an event happens, being the first news article that has been published means that for a short period of time, the news article doesn’t have a similar example, or any kind of competition. Thus, a regency score is also important to evaluate the unique value of a news article.
Even if a news article has a better unique information gain score, it doesn’t mean that the specific news article will be understood clearly by the search engine. To provide a better news article of unique value, the historically relevant information, content, and other related entities should be presented with at least one or two clicks away from the main news article.
If a search engine finds that the content recommendation system, and the news coverage for the specific entity, related entity, and all of the possible contexts, the news source will have a better topical coverage, and authority for the specific topic.
At the left upper section, you see that Google can create “word pairs' ', and match the context by performing deduplication. At the left section, the same word pairs’ context is reflected as internal links, and their place’s prominence. At the left bottom section, you see that “focusing on concepts” are more important than matching phrases. In this context, the concept is the entity.
During this article, I didn’t focus on authorship, but a search engine can understand the value of a news article also based on the journalist. Like the news source, journalist is also a qualifier for the news article. If the journalist is authoritative for the topic, the news article will have a better chance to be ranked, since the other relevant documents, and news articles will be reachable based on the journalist’s profile.
A search engine can divide a news source based on different news topics, entities, or journalists. A news source can have different sites, based on the point of view. Thus, the unique value of the news article is also related to the possible news site sections based on topic, interest area, and journalist.
HOW TO USE NAMED ENTITY RECOGNITION FOR NEWS ARTICLES?
Named Entity Recognition is the process of recognizing named entities within the textual data. It can help for a machine to understand the topic of a content. It is also helpful to support the Information Retrieval technologies.
In a news article, the entities can be recognized via named entity recognition of search engines. Recognizing entities’ closeness within the article, and having the related phrases around them in the textual data is important to improve the contextual relevance. And, having semantically close entities at the same paragraph with the proper lexical semantics is also important to develop a clear relevance signal. Named entity recognition can be used also for only the news headlines. If the entities from a news headline can be extracted, the main context, or the topic can be extracted faster.
A news site can perform a simple A/B Test to understand the value of including the named entity within the news headline, and the introduction of the news article. More related entities, more related attributes at the news article’s contextually important points will result in better rankings thanks to the more clear signals.
A sample from “Named Entity Recognition with Visual, and textual Queries”, along with NTV.com.tr as a sample news website.
How to Use Semantic Role Labeling for News Articles?
Semantic Role Labeling is related to the Named Entity Recognition. Semantic Role Labeling is the process of giving a label to every word within a sentence based on the predicate of a sentence. As a sample, within the sentence of “Joe Biden has signed the bill for retrieving US Troops from Afghanistan”, the “bill” is the theme, “Joe Biden” is the “agent”, the “sign” is the predicate. For the same news, a search engine can gather all of the related news articles and filter them based on the semantic role labeling.
A news article’s point of view, its prepositions, or the facts can be understood easily by the search engine. In some news articles the predicate and the agent will change, and the theme, sentiments and other types of features related to the semantic SEO will vary.
A search engine can try to filter news articles based on sentiment, and also semantic role labeling. If a news source is against the Covid-19 Vaccines, a search engine can detect the anti-science stance on the news source based on the semantic role labeling. Thus, search engines can also use semantic role labeling, and also sentiment to see the accuracy, comprehensiveness and the factuality of the content.
A Section from “Analysis of Meaning” presentation for demonstrating the Semantic Roles.
HOW TO USE QUERY AND DOCUMENT TEMPLATES FOR SEMANTIC-NEWS SEO?
A search engine can detect a template based on the news genre. In every news genre, there can be a different type of news template. A search engine can decide to not rank a certain news template due to unclarity, complexity, or the missing information.
Thus, while creating a news template, the query templates, and the semantically prominent entities, and attributes for the specific news genre should be used.
What is a News Template?
A news template is the template that is generated for a specific topic. A topic can be expressed by certain types of news article template to explain the most important details. For instance, in Search Engine Land, Barry Schawrtz has useful news templates for the search engine optimization related updates and events.
Barry Schawrtz always explains the topic with the related entities, and always uses the text styling as below.
So, the importance of the update, why we should care about it, and what are the important points, all of them can clearly be seen. In this context a news article template should include the things below.
The most important related entities.
The most important entity attributes
The main context
The main entity
The sub-contexts, and the semantic annotations for internal links.
Essence of the event, prepositions, facts, and an expanding article structure with headings
Recommendation for historically prominent and relevant news articles
Recommendation for the related entities for similar contexts
You can tell me what is the difference between semantically structured news articles, and news article templates. In the news article template, the sentences do not have to change. Only the entities, attributes and the information change. In other words, if the news is about murder, there is a cause, and the result, along with a time, and a place. You can create the best possible sentence structure to give the context, relevance and the information. And, by time the news article template can be improved. In the semantically structuring news article section, it doesn’t include the sentence structures, it includes the order of the information, and general aspect of the context.
A section from the research of Seth C. Lewis from University of Oregon, related to the readability and authenticity of a news story. It shows that the authenticity of a news story and its readability are connected to each other. And, to create a readable, authentic news article template, you will need to consider the length, and information-fact presentation style.
How to Create a News Template for Every News Genre?
To create a news article template for a specific genre, the news genre's important features and information points should be included. For a race event, or a celebration, the tonality, entities, attributes, and context will change according to an international business agreement between Russia and Germany. But, for every news genre, based on the news’ nature, there are some mutual things that can be used such as a time, a place, a cause, a result, an effect, and an actor.
Based on the news’ genre, different types of causes, results, effects, actors, and factors will be used, and their order will also be changed. Thus, if it is an earthquake news, you will need its “intensity”, and “effect” with visual and textual evidence at the beginning of the news article. If it is a stock market manipulation, you will need to include its effects, and organization at the beginning. After choosing the important attributes, and news’ components, you should create the proper sentence structures with the proper content tonality, and sentiment.
I would suggest you check the GDELT project of Google to recognize all of the news around the planet by clustering them to understand the news, news sources, and information-disinformation on the planet. You will see that they distribute the news to the different genres, and sources based on their prominence.
If the topic is about a concert, or an artwork, and if the news article includes criticism, then the sentiment will be different, and the news article will be evaluated differently in the eyes of the search engine. Based on the news genre, to create a news article template for semantic news SEO, you can follow the steps below.
Understand the news genre’s important factors.
Include all of the important factors by connecting them to each other to give information.
Use subheading for every sub-factor as long as it has a prominence.
For every news genre, a different sub-factor can have multiple, singular subsections.
For every news genre, different subfactors can share the same subsection.
Use the correct tonality, and sentiment for the correct news genre.
Include the main entities within the title, and define the news’ context at the beginning of the news article.
Use the properly parseable sentences by the search engine during the Natural Language Processing and Understanding.
Test different sentences, headings, titles, and news article templates with A/B tests.
You will see that they distribute the news based on themes, concepts, timelines, geographies, and also they create word clouds, and more semantic organization for news.
Last Thoughts on Semantic-News SEO based on News Related Entities, and Newsworthy Context
Google has improved its semantic nature tremendously with the latest algorithmic updates such as BERT, Neural Nets, MuM, LaMDA. And, there is more research that they do based on question generation, question ranking, question-answer matching, and search intent understanding. Thus, News SEO also started to have a more semantic nature. Most people thought that Semantic SEO is only for evergreen informative pages based on the PAA questions, but actually it is about all of the web since the web is also semantic. Semantic Search was mentioned by Tim Barners Lee 22 years ago, and one year later, Google’s founder Sergey Bring used the “semantic search engine” term for the first time within one of his parents. Today, within Google Trends, and Google News, along with Google Discover, we see topics, entities, n-grams, structured sentences, contextually relevant links, named entity recognition. Google can understand the factuality, and accuracy of a news article, and it can value the journalist, along with understanding the relationship between newsworthy entities based on a context. Because of this, I recommend every News SEO to organize their news sources based on semantics, and I am sure that they will see a big traffic increase especially for the Google Discover.
Writing this article was not easy, when it comes to the News SEO, it definitely deserves a different vertical of SEO. Like, Technical SEO, Semantic SEO, On Page SEO, Off Page SEO, Barnacle SEO, Influencer SEO and more, News SEO is one of the most fundamental SEO verticals. When it comes to News SEO with Semantic Search Understanding, it has more value since Google started to reorganize the news related information on the web based on topics.
Semantic News SEO, or News SEO with Semantic SEO Principles might be a little bit of a new term for the SEO Industry. Thus, writing this Semantic News SEO Manifesto, at the biggest News SEO Technology NewzDash’s official website has become an honor that I will remember in the future.
Lastly, I want to give a small advice to News SEOs, based on Semantic News SEO understanding:
Focus on the Entities that You Are Prominent Enough
At the last section of the Semantic News SEO, the “entities that a news source is prominent” should be known. In other words, from Google Discovery to Google News, search engines will choose certain news sources as the authority. And, if a news source produces more content for the entities, topics, and contexts that it is already authoritative, it will produce more organic traffic.
In this context, the distribution of the news and their themes on the homepage can affect the Top Stories and Google Discover effect for a news source. If the news source has many magazine entities, and topics on the homepage, Google might think that this source is more authoritative, and relevant for these topics. In this context, a news site can use entities, and topics as a news source identity signal for having the ranking priority in trending topics.
If a news source wants to be more authoritative for a specific topic, it means that it will need more historically prominent, clearly structured, and semantically connected entity-oriented news articles.
The same structure can be seen also for the Washington Post.
But, focusing on the topics that the news source is already authoritative can improve a news source’s Google Discover traffic by multiplying it 3, or 4. Google Discover focuses on the entities, and interest areas. If a source is authoritative for specific entities, contexts, topics, and interest areas, it can earn an extensive amount of traffic by even multiplying the Google News, and Web Search organic performances.
And, you can check how they perform for the specific entity, topics and its trending news related search queries.
In the future articles, we will process more news SEO related subjects based on concrete documents, and practical SEO samples.
Koray Tuğberk GÜBÜR is the founder of Holistic SEO & Digital. He focuses on different verticals of SEO such as Data Science, Web Development, Search Engine Patents, and Methodologies. Koray publishes SEO Case Studies and articles regularly.